애플에서 공개한 AI 모델, 'DiffuCoder'를 소개합니다. | 오픈소스 AI | 디퓨전모델 | dLLM
애플의 AI 모델, DiffuCoder 공개
최근 다양한 테크 기업들이 고성능 AI 모델을 앞다투어 공개하며 경쟁이 치열해지고 있습니다. 이러한 흐름 속에서 애플도 독자적인 접근을 통해 본격적으로 AI 모델 경쟁에 참여하고 있습니다. 올해 초 발표된 디퓨전 기반 언어 모델(dLLM) 기술을 바탕으로, 애플은 해당 구조를 적용한 DiffuCoder 모델을 공개하였습니다.
이 글에서는 애플이 선보인 DiffuCoder 모델이 무엇인지, 그리고 그 특징과 간단한 사용 예시에 대해 알아보겠습니다.
DiffuCoder란 무엇인가요?
DiffuCoder는 Apple에서 개발한 70억 매개변수(7B) 규모의 대규모 언어 모델(LLM) 입니다. 이 모델은 특히 코드 자동 완성 및 생성 작업에 특화되어 있으며, 텍스트 설명(자연어)을 파이썬 코드로 변환하는 데 뛰어난 성능을 보입니다.
가장 큰 특징은 기존 LLM들과 달리 확산 모델(Diffusion Model) 의 원리를 코드 생성에 접목했다는 점입니다. 이 새로운 접근 방식 덕분에 복잡한 코드도 더 정교하고 일관성 있게 만들어낼 수 있습니다.
핵심 동작 원리: 확산과 병렬 처리
그렇다면 DiffuCoder는 기존 모델과 어떻게 다르게 작동할까요? 핵심은 '생성 방식' 에 있습니다.
- 기존 LLM: 왼쪽부터 오른쪽으로 한 단어씩 순차적으로 코드를 이어 붙입니다. 단일 요청은 빠르지만, 여러 요청을 동시에 처리하기 어렵고 문맥이 길어지면 일관성을 잃기 쉽습니다.
- DiffuCoder (dLLM): 먼저 전체 코드의 초안을 빠르게 만들고, 그 다음 코드 전체를 동시에 보며 흐릿한 이미지를 선명하게 만들 듯 여러 번에 걸쳐 병렬로 다듬어 완성합니다.
이러한 '반복적 정제' 방식은 두 가지 강력한 장점을 가집니다.
- 높은 정확도: 전체 코드의 구조와 문맥을 계속 참고하며 개선하므로, 복잡한 논리에서도 일관성 높은 코드를 생성합니다.
- 압도적인 처리량: 전체 코드를 동시에 처리하는 구조 덕분에 GPU의 병렬 처리 능력을 극대화할 수 있습니다. 그 결과, 수많은 코드 생성 요청을 한 번에 처리하는 능력(Throughput)이 매우 뛰어납니다.
| 항목 | 기존 LLM (Large Language Model) | dLLM (Diffusion LLM) |
|---|---|---|
| 생성 방식 | 왼쪽부터 오른쪽으로 한 토큰씩 순차 생성 | 초안 생성 후 반복적으로 전체 시퀀스를 정제 |
| 대표 모델 예시 | GPT, LLaMA, Mistral 등 | Mercury Coder, Apple DiffuCoder 등 |
| 코드 생성 정확도 | 짧고 단순한 코드는 우수하나, 복잡한 논리에는 한계 | 복잡한 로직에서도 일관성 있고 정확한 코드 생성 가능 |
| 속도 (단일 생성) | 빠름 (단일 패스 방식) | 상대적으로 느림 (반복적 정제 과정 필요) |
| 속도 (대량 처리) | 느림 (요청을 순차적으로 처리) | 매우 빠름 (병렬 처리 능력 극대화) |
| 활용 분야 | 일반 텍스트 생성, 요약, 번역 등 | 코드 생성, 정밀 편집, 고정밀 텍스트 생성 등 |
| 구조적 특징 | 디코더 중심 | 디코더 기반 + 반복 정제 모듈 |
주요 특징
- 반복적 정제 (Iterative Refinement): 코드를 왼쪽부터 순서대로 한 번에 써 내려가는 것이 아니라, 먼저 전체 코드의 밑그림(초안)을 만든 뒤 여러 번에 걸쳐 전체를 훑어보며 어색한 부분을 수정하고 완성도를 높여나가는 방식입니다.
- 자기회귀성 점수 (Autoregressiveness Score): AI가 코드를 생성할 때 얼마나 '정해진 순서대로' 작업하는지를 점수로 나타내는 독자적인 지표입니다. 개발자는 이 점수를 조절해 AI의 작업 방식을 제어할 수 있습니다.
- 결합-GRPO 강화학습 (Coupled-GRPO Reinforcement Learning): DiffuCoder 모델에 최적화된 특별한 맞춤형 훈련 방식입니다. 이 훈련을 통해 코드의 정확도를 크게 끌어올렸습니다.
- 사전학습 (Pre-training): AI가 세상에 나오기 전, 약 1,300억 단어 분량의 방대한 코드 데이터를 미리 공부하는 과정입니다. 이를 통해 다양한 코드 생성 능력을 위한 탄탄한 기본기를 갖추게 됩니다.
- 유연한 생성 패턴 (Flexible Generation Pattern): AI의 창의력을 조절하는 독특한 기능입니다. 단순히 다양한 단어를 쓰는 것을 넘어, '어디부터 코드를 수정할지' 그 작업 순서 자체를 바꾸는 방식으로 더 새롭고 창의적인 결과물을 만들어냅니다.
라이선스
DiffuCoder-7B-Instruct는 Apple의 샘플 코드 라이선스(Copyright Apple Inc. 2025) 에 따라 제공됩니다. 해당 라이선스는 다음과 같은 조건 하에 모델을 사용할 수 있도록 허용합니다.
- 사용 및 수정: 개인 또는 기관은 DiffuCoder의 소스 및 바이너리 형태를 자유롭게 사용하고 수정할 수 있습니다.
- 재배포 허용: 원본 또는 수정된 형태 모두 재배포가 가능하며, 이때 반드시 원본 저작권 고지와 면책 조항을 그대로 유지해야 합니다.
- 상업적 이용 가능: 라이선스 내에서 상업적 사용을 별도로 금지하지 않으므로, 상업적 목적의 활용도 가능하지만, Apple의 이름, 로고, 상표 등을 사용한 홍보는 명시적인 서면 허가 없이 불가합니다.
- 특허권 제외: 본 라이선스는 Apple의 특허권을 포함하지 않으므로, 사용자는 특허 관련 위험성을 자체적으로 검토해야 합니다.
- 무보증 제공: Apple은 해당 소프트웨어에 대해 명시적 또는 묵시적인 보증을 제공하지 않으며, 사용으로 인한 모든 책임은 사용자에게 있습니다.
이러한 조건을 준수한다면, DiffuCoder는 연구 개발, 제품 프로토타입, 교육 등 다양한 목적으로 유연하게 활용할 수 있습니다.
- 애플 깃허브 (DiffuCoder 라이선스) : https://github.com/apple/ml-diffucoder/blob/main/LICENSE
간단한 사용 방법
DiffuCoder는 허깅페이스에서 모델을 다운로드한 뒤, 간단한 코드로 바로 사용할 수 있습니다.
⚠️주의 : 7B 모델은 실행을 위해 충분한 시스템 메모리(RAM) 와 GPU VRAM이 필요합니다. 따라서 GPU 환경 또는 Google Colab Pro와 같은 고사양 환경에서의 실행을 권장합니다.
1. 모델 다운로드
아래 허깅페이스에서 DiffuCoder-7B-Instruct 모델을 다운로드할 수 있습니다.
2. 패키지 설치
모델을 실행하기 위해 필요한 주요 라이브러리를 먼저 설치합니다.
# Windows PowerShell
pip install transformers accelerate
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu126
- transformers: 허깅페이스의 모델 및 토크나이저를 로드하는 핵심 라이브러리입니다.
- accelerate: 모델을 여러 GPU나 CPU에 효율적으로 분산 로드하여 메모리 부담을 줄여줍니다.
- torch: 파이토치(PyTorch) 기반 딥러닝 프레임워크로, 위 명령어는 CUDA 지원 버전을 설치하는 예시입니다.
3. 실행 코드 예시
아래는 애플 허깅페이스에서 제공하는 예시 코드를 사용했습니다.
# Python
import torch
from transformers import AutoModel, AutoTokenizer
model_path = "apple/DiffuCoder-7B-Instruct" # 사용자 환경에 맞게 수정
model = AutoModel.from_pretrained(model_path, torch_dtype=torch.bfloat16, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = model.to("cuda").eval()
query = "Write a function to find the shared elements from the given two lists."
prompt = f"""<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{query.strip()}
<|im_end|>
<|im_start|>assistant
""" ## following the template of qwen; you can also use apply_chat_template function
TOKEN_PER_STEP = 1 # diffusion timesteps * TOKEN_PER_STEP = total new tokens
inputs = tokenizer(prompt, return_tensors="pt")
input_ids = inputs.input_ids.to(device="cuda")
attention_mask = inputs.attention_mask.to(device="cuda")
output = model.diffusion_generate(
input_ids,
attention_mask=attention_mask,
max_new_tokens=256,
output_history=True,
return_dict_in_generate=True,
steps=256//TOKEN_PER_STEP,
temperature=0.3,
top_p=0.95,
alg="entropy",
alg_temp=0.,
)
generations = [
tokenizer.decode(g[len(p) :].tolist())
for p, g in zip(input_ids, output.sequences)
]
print(generations[0].split('<|dlm_pad|>')[0])
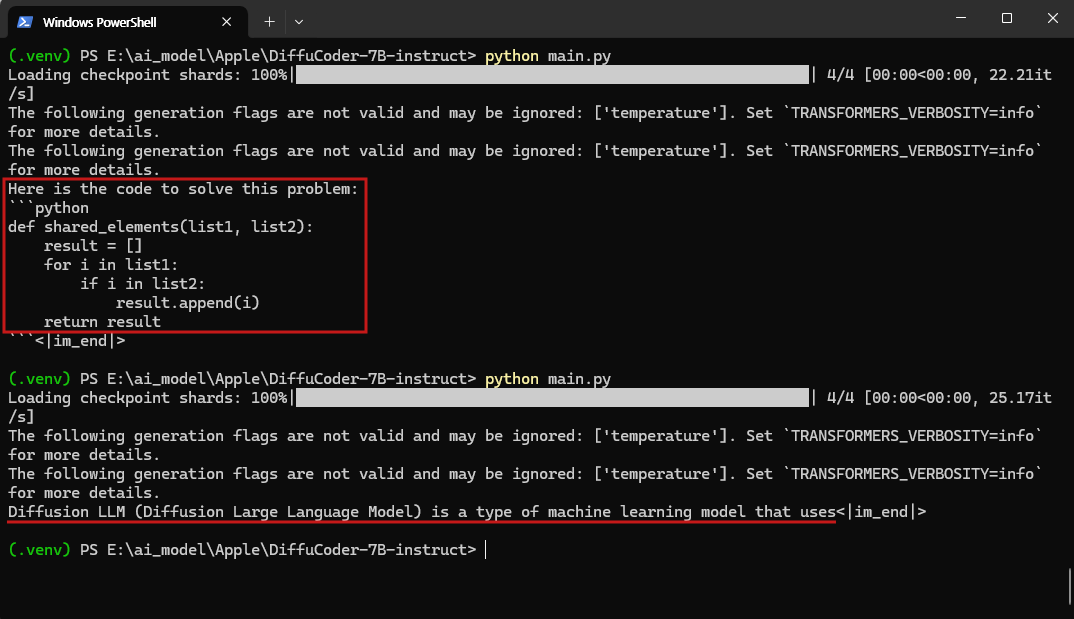
4. 실행 결과
DiffuCoder-7B-Instruct 모델은 로컬 환경에서 직접 실행하였습니다. 테스트를 위해 두 개의 프롬프트를 입력하여 총 2회의 응답 결과를 확인하였습니다.
사용한 프롬프트는 다음과 같습니다.
- 프롬프트 1 : "Write a function to find the shared elements from the given two lists."
- 프롬프트 2 : "dLLM (Diffusion LLM) 모델에 대해 설명해줘."
모델 실행 시 약 16.1GB의 GPU VRAM이 사용되었으며, 한 번의 추론에 걸린 시간은 평균적으로 약 1분 내외였습니다.
영어로 작성된 프롬프트에 대해서는 자연스럽고 정확한 파이썬 코드를 생성하였고, 한글로 작성된 질문에 대해서도 무리 없이 내용을 이해하고 응답하는 모습을 확인할 수 있었습니다.
DiffuCoder는 코드 생성뿐 아니라 개념 설명과 같은 인스트럭션 응답에서도 안정적인 출력을 보여주었으며, 전반적으로 신뢰할 수 있는 응답 품질을 제공하였습니다.
아래는 해당 테스트의 실제 실행 결과 화면입니다.
마치며
애플의 DiffuCoder 모델은 기존 LLM과는 다른 기술적 접근 방식을 제시했다는 점에서 의미가 큽니다. 특히 기존의 순차 생성 방식이 가진 한계를 '반복적 정제(Iterative Refinement)' 라는 독창적인 구조로 극복하며, 복잡한 코드에 대한 정확도와 대규모 요청에 대한 처리 효율성이라는 두 가지 핵심 장점을 모두 갖추고 있습니다. 보다 정확하고 빠른 결과를 제공할 수 있다는 점에서, 앞으로의 코드 생성 AI 모델의 발전 방향을 보여주는 사례라 할 수 있습니다.
관심 있는 분들은 직접 모델을 실행해 보시고, DiffuCoder의 성능을 체험해보시길 권장드립니다.
감사합니다.
[참고 링크]
👉 애플 깃허브 : https://github.com/apple/ml-diffucoder
👉 애플 허깅페이스 : https://huggingface.co/apple/DiffuCoder-7B-Instruct/