Gemma 3n: 모바일·엣지 시대를 겨냥한 구글의 차세대 경량 멀티모달 모델
2GB RAM에서도 작동하는 초경량 LLM, 텍스트·이미지·오디오까지 모두 처리한다
Gemma 3n은 구글이 2025년 5월 20일에 프리뷰를 공개한 초경량 멀티모달 언어 모델(Small Language Model, SLM) 입니다. 이 모델은 단 2GB RAM만으로도 텍스트, 이미지, 오디오, 영상 등 다양한 입력을 온디바이스 환경에서 실시간으로 처리할 수 있도록 설계되었습니다. 특히, 기존 Gemma 3 시리즈가 입증한 고성능을 그대로 유지하면서도, 스마트폰, 태블릿, 노트북 등 제한된 하드웨어에서도 빠르고 효율적으로 작동하는 것이 큰 강점입니다. 이를 통해 모바일 및 엣지 컴퓨팅 환경에서도 프라이버시를 보장하며 강력한 AI 경험을 제공할 수 있게 되었습니다.
제공 버전
| 모델 | 이름 | 실질 파라미터 | 요구 메모리 | 특징 |
|---|---|---|---|---|
| E2B | Gemma 3n 2B | 2 B | 약 2 GB RAM | 모바일·임베디드 최적화 |
| E4B | Gemma 3n 4B | 4 B | 약 3 GB RAM | 고품질·저지연 균형형 |
두 버전은 Matryoshka Transformer(MAT) 구조 덕분에 하나의 체크포인트 안에 포함되어 있으며, 실행 중 자유롭게 2B ⇄ 4B 모드 전환이 가능합니다.
주요 특징
-
MatFormer 통합 구조
- 하나의 모델 안에 두 가지 크기의 버전(E2B, E4B)이 함께 들어 있어, 상황에 따라 속도를 빠르게 하거나 정확도를 높이도록 실시간으로 조절할 수 있습니다.
-
Per-Layer Embeddings (PLE)
- 인공지능이 기억해야 할 데이터 일부를 그래픽 메모리(VRAM)가 아니라 일반 메모리(CPU 메모리)에 저장해, 더 적은 자원으로도 똑똑하게 작동할 수 있습니다.
-
KV Cache Sharing
- 음성이나 영상처럼 길고 복잡한 입력을 처리할 때, 반응 속도를 2배 더 빠르게 만들어 기다리는 시간을 줄여줍니다.
-
멀티모달 인코더
- 오디오: 사람 목소리를 30초 정도 녹음하면, 이를 바로 글자로 바꾸거나 의미를 파악합니다.
- 비전: 카메라 영상도 실시간으로 이해할 수 있어, 스마트폰처럼 작은 기기에서도 빠르게 처리할 수 있습니다.
-
완전 오프라인 실행
- 인터넷에 연결되지 않아도 인공지능이 작동하며, 개인정보가 외부로 나가지 않아서 더욱 안전합니다.
-
140개 언어 지원
- 한국어를 포함해 140개 이상의 언어를 이해하고 번역할 수 있어, 다양한 언어 환경에서 유용하게 사용할 수 있습니다.
성능 비교
Gemma 3n은 빠른 속도와 높은 성능을 모두 갖춘 소형 AI 모델입니다. 모바일 환경에서 이전 모델인 Gemma 3 4B보다 약 1.5배 더 빠르게 응답하므로, 작은 기기에서도 빠르고 부드럽게 작동합니다.
AI 모델들의 경쟁력과 인기도를 보여주는 Chatbot Arena 순위에서는, Gemma 3n이 1283점을 기록하며 상위권에 올랐습니다. 이 점수는 대형 모델인 GPT-4.1 nano나 Llama 4보다도 높고, 소형 모델 중에서는 처음으로 이 정도 순위에 진입한 모델입니다.
무엇보다도 Gemma 3n은 그래픽 메모리(VRAM)를 기존 모델보다 30% 이상 적게 사용합니다. 그래서 고사양 장비가 없어도, 2~3GB 메모리만 있으면 로컬에서도 실행할 수 있다는 점이 큰 장점입니다.
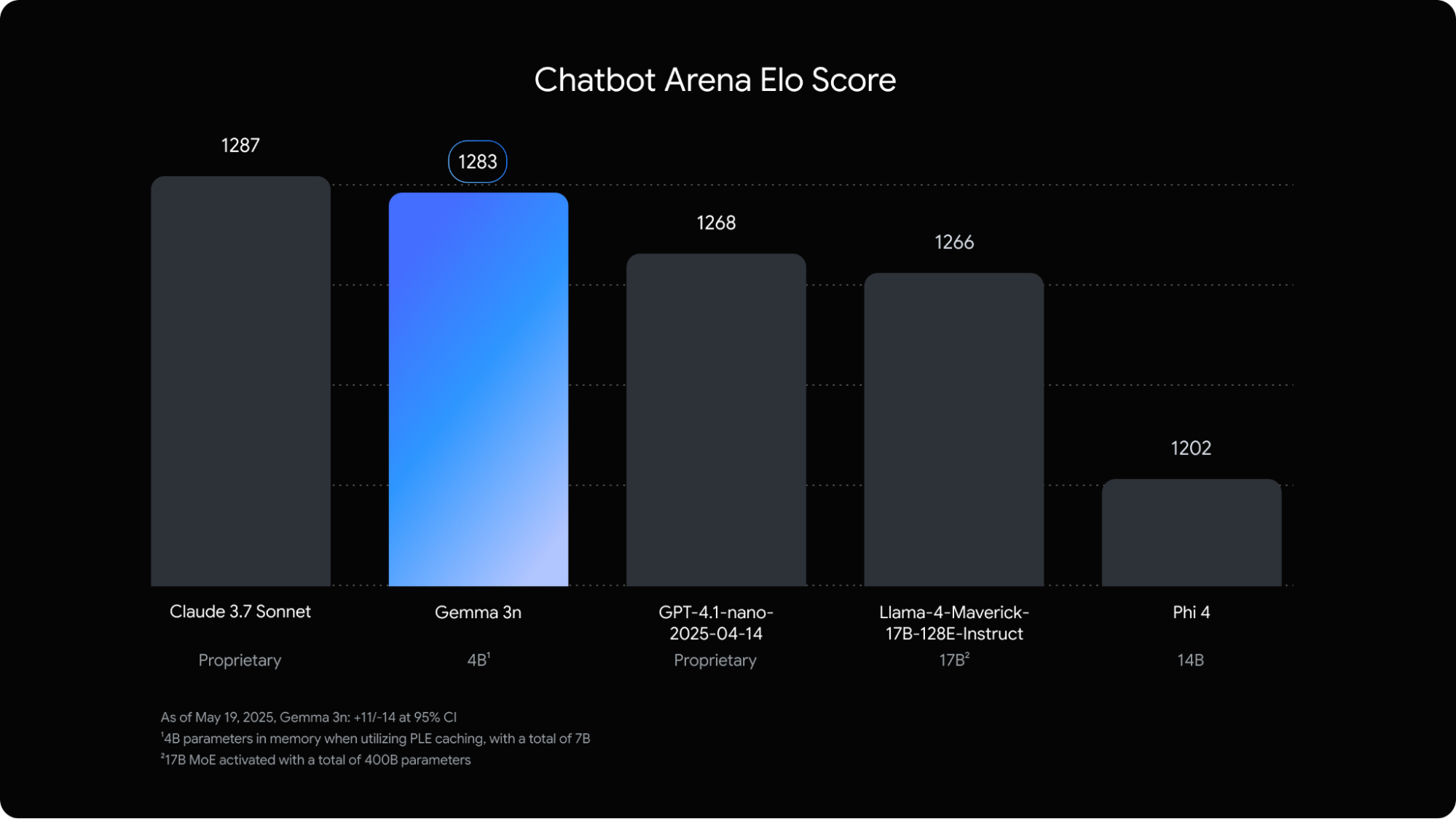
[비교 요약]
- 응답 속도: Gemma 3 4B 대비 모바일 체감 속도 1.5배 향상
- Chatbot Arena: 10B 미만 최초로 상위권 진입
- VRAM 사용량: 동일 크기 경쟁 모델 대비 30% 이상 절감
라이선스 및 사용 조건
Gemma 3n은 Google DeepMind가 공개한 오픈 모델로, 연구 및 상업적 목적을 포함한 다양한 용도로 자유롭게 사용할 수 있습니다. 이 모델은 Gemma 라이선스 하에 배포되며, 사용자가 생성한 결과물(Output)의 소유권은 사용자에게 있으며, 자유롭게 활용할 수 있습니다.
단, 다음과 같은 조건과 제한 사항을 반드시 준수해야 합니다.
- 모델 또는 파생 모델을 외부에 공개하거나 재배포할 경우, Gemma 라이선스 사본을 함께 제공해야 합니다.
- API나 웹서비스 등으로 제공하는 경우, 이용약관 및 사용 제한 사항을 명시적으로 고지해야 합니다.
- 의료, 군사, 불법 활동 등 금지된 용도에는 사용할 수 없습니다.
- 안전성, 프라이버시 보호, 유해 콘텐츠 방지 등 Google이 제시한 책임 있는 AI 사용 가이드라인을 따라야 합니다.
- Google의 이름, 로고, 후원 또는 제휴를 암시하는 표현은 사용할 수 없습니다.
이와 같은 조건을 준수하는 범위 내에서, Gemma 3n은 누구나 부담 없이 활용 가능한 고성능 온디바이스 AI 모델입니다.
Gemma 라이선스 : https://ai.google.dev/gemma/terms
이용 가능한 플랫폼 및 도구
| 플랫폼 | 지원 내용 |
|---|---|
| Google AI Studio | 브라우저 기반 데모·튜토리얼 제공 |
| Google AI Edge SDK | Android·Chrome 기기용 배포 키트 |
| Hugging Face / Kaggle | 모델 가중치(E2B·E4B) 다운로드 제공 |
| Ollama / llama.cpp / MLX | 로컬·서버·브라우저 실행 스크립트 제공 |
마무리
Gemma 3n은 “작지만 강력한” 온디바이스 멀티모달 AI의 가능성을 현실로 만든 대표적인 사례입니다. 텍스트는 물론 이미지, 음성, 영상까지 처리할 수 있는 멀티모달 능력과, 2GB RAM 환경에서도 원활하게 작동하는 경량화된 구조는 다양한 하드웨어 환경에서의 활용 가능성을 넓혀주었습니다.
특히 오픈소스 기반으로 제공되는 점과 Google이 제공하는 다양한 실행 도구 덕분에, 개인 개발자부터 스타트업, 대기업에 이르기까지 누구나 손쉽게 프라이버시 중심의 실시간 AI 시스템을 구축할 수 있습니다. 복잡한 클라우드 설정 없이도, 빠르고 민첩한 AI 환경을 직접 구축해보세요.
[참고 링크]
👉 구글 딥마인드 : https://deepmind.google/models/gemma/
👉 구글 블로그 (Gemma3n) : https://developers.googleblog.com/en/introducing-gemma-3n/
👉 구글 허깅페이스 (Gemma3n) : https://huggingface.co/collections/google/gemma-3n-685065323f5984ef315c93f4
👉 Gemma 라이선스 : https://ai.google.dev/gemma/terms