구글의 Gemma 3 270M, 초소형 AI 모델 소개와 로컬 실행 가이드 | 오픈소스 AI
작고 빠른 구글의 초소형 AI모델, Gemma 3 270M 🚀
구글이 오픈 소스 AI 모델 시리즈인 Gemma 3를 선보인 이후, 다양한 크기의 모델들이 공개되어 왔습니다. 그리고 이번에는 그중에서도 가장 작고 효율적인 Gemma 3 270M 버전이 새롭게 공개되어 주목을 받고 있습니다. 크기가 1GB도 되지 않을 만큼 가볍지만, 뛰어난 효율성과 성능을 갖추어 온디바이스 환경에서도 원활히 활용할 수 있어 많은 관심이 모였습니다.
이번 글에서는 Gemma 3 270M 모델의 특징과 함께, Ollama 및 Python 코드 예시를 통한 간단한 사용법을 소개합니다.
Gemma 3 270M 모델이란
Gemma 3 270M 모델은 구글이 2025년 8월 14일에 새롭게 공개한 초소형 언어 모델(SLM, Small Language Model)입니다. 이름에서 알 수 있듯이 약 2억 7천만(270M) 개의 파라미터(parameter) 를 탑재하고 있으며, 크기가 1GB도 되지 않을 정도로 가볍게 설계되었습니다.
이 모델은 대규모 언어 모델(LLM)과 달리 온디바이스(On-Device) 실행에 최적화되어 있어, 스마트폰이나 노트북 같은 개인 기기에서도 원활히 동작할 수 있습니다. 또한 빠른 속도, 낮은 자원 사용량, 특정 작업에 대한 높은 효율성을 목표로 개발되어, 실험적 연구부터 상용 애플리케이션까지 다양한 분야에서 활용할 수 있는 잠재력을 갖추고 있습니다.
[모델 정보]
| 항목 | 내용 |
|---|---|
| 모델명 | Gemma 3 270M |
| 파라미터 수 | 270M (2억 7천만) |
| 개발사 | |
| 출시일 | 2025년 8월 14일 (현지 시간) |
| 컨텍스트 길이 | 최대 32K 토큰 입력 및 출력 |
| 특징 | 가볍고 효율적인 구조, 온디바이스 모델 |
| 라이선스 | “Gemma” 사용 약관 기반 라이선스 |
주요 특징
⚡️ 뛰어난 효율성과 속도
- 작은 모델 크기로 인해 적은 자원에서도 빠르게 동작합니다.
- 노트북이나 스마트폰과 같은 온디바이스(On-Device) 환경에서도 실행가능하며, 서버 비용 절감에 유리합니다.
- 구글 테스트 기준, Pixel 9 Pro에서 25회 대화 시 배터리 소모가 1% 미만일 정도로 전력 효율이 뛰어납니다.
🎯 특정 작업 최적화
- 일반 대화보다는 텍스트 분류, 감성 분석, 데이터 추출 등 특정 작업 수행에 강점이 있습니다.
(일반 대화(챗봇, 논리 추론, 창의적 응답 등) 의 경우 대형 범용 모델에 비해 성능에 한계가 있을 수 있음.) - 파인튜닝(Fine-tuning)을 통해 원하는 용도에 맞게 손쉽게 특화시킬 수 있습니다.
🔒 개인정보 보호 강화
- 외부 서버 전송 없이 기기 내 처리(On-device) 가 가능하여, 민감한 정보를 다루는 애플리케이션에 적합합니다.
👨💻 개발자 친화성
- Hugging Face, Kaggle, Google AI Studio 등 다양한 플랫폼에서 쉽게 접근할 수 있습니다.
- 파인튜닝 실험과 배포 주기를 며칠 → 몇 시간 단위로 단축할 수 있습니다.
👉 정리하자면, Gemma 3 270M은 빠르고, 저렴하며, 안전하게 AI를 활용하려는 개발자와 연구자에게 이상적인 선택지입니다.
벤치마크 성능
현재 Gemma 3 270M 모델의 벤치마크 성능은 허깅페이스를 통해 공개되어 있으며, 학습 방식에 따라 두 가지 형태로 나누어 살펴볼 수 있습니다.
- PT 모델(Pretrained) 은 대규모 텍스트 데이터를 기반으로 학습된 기본형 모델로, 언어 이해와 지식 기반 질의응답에 강점을 보입니다. 모델 크기가 커질수록 정확도와 추론 능력이 크게 향상되는 특징을 보입니다.
- IT 모델(Instruction-Tuned) 은 PT 모델을 기반으로 지시문과 정답 데이터를 추가 학습한 버전으로, 사용자의 요청을 이해하고 이에 맞게 응답하는 데 최적화되어 있습니다. 특히 IFEval과 같은 지시문 수행 평가에서는 PT 모델보다 훨씬 높은 성능을 기록합니다.
정리하자면, PT 모델은 지식·언어 이해 중심의 기본형, IT 모델은 지시문 수행과 대화 중심의 실사용형으로 구분할 수 있습니다.
아래는 Gemma 3 270M 모델의 벤치마크 성능을 정리한 표입니다.
[Gemma 3 PT 모델 비교]
| Benchmark | n-shot | Gemma 3 PT 270M | Gemma 3 PT 1B | Gemma 3 PT 4B | Gemma 3 PT 12B | Gemma 3 PT 27B |
|---|---|---|---|---|---|---|
| HellaSwag | 10-shot | 40.9 | 62.3 | 77.2 | 84.2 | 85.6 |
| BoolQ | 0-shot | 61.4 | 63.2 | 72.3 | 78.8 | 82.4 |
| PIQA | 0-shot | 67.7 | 73.8 | 79.6 | 81.8 | 83.3 |
| TriviaQA | 5-shot | 15.4 | 39.8 | 65.8 | 78.2 | 85.5 |
| ARC-c | 25-shot | 29.0 | 38.4 | 56.2 | 68.9 | 70.6 |
| ARC-e | 0-shot | 57.7 | 73.0 | 82.4 | 88.3 | 89.3 |
| WinoGrande | 5-shot | 52.0 | 58.2 | 64.7 | 74.3 | 78.9 |
- HellaSwag : 상식적 추론과 문맥 이해 능력
- BoolQ : 질문에 대해 참·거짓을 정확히 판별하는 능력
- PIQA : 물리적 상식과 일상적 상황 판단 능력
- TriviaQA : 사실 기반의 지식 검색 및 응답 능력
- ARC-c : 과학적 개념이 포함된 복잡한 문제 해결 능력
- ARC-e : 기본 과학 지식을 활용한 문제 해결 능력
- WinoGrande : 대명사와 문맥을 올바르게 해석하는 능력
[Gemma 3 IT 모델 비교]
| Benchmark | n-shot | Gemma 3 IT 270M | Gemma 3 IT 1B | Gemma 3 IT 4B | Gemma 3 IT 12B | Gemma 3 IT 27B |
|---|---|---|---|---|---|---|
| BIG-Bench Hard | few | 26.7 | 39.1 | 72.2 | 85.7 | 87.6 |
| IFEval | 0-shot | 51.2 | 80.2 | 90.2 | 88.9 | 90.4 |
- BIG-Bench Hard : 난도가 높은 추론 및 복합적 사고 능력
- IFEval : 사용자의 지시문을 올바르게 이해하고 수행하는 능력
라이선스
Gemma 3 270M 모델은 구글에서 제시한 Gemma 라이선스를 따릅니다. 이 라이선스는 Apache 2.0과 유사한 오픈소스 라이선스 성격을 가지지만, 몇 가지 추가 조건이 포함되어 있습니다.
- 상업적 사용 가능 : 연구, 개인 프로젝트, 기업 서비스 등 다양한 목적에 활용할 수 있습니다.
- 수정 및 배포 허용 : 모델을 재학습하거나 변형하여 배포할 수 있습니다. 다만, 반드시 Gemma 라이선스 조건을 준수해야 합니다.
- “Gemma” 명칭 사용 제한 : 모델을 수정·재배포할 경우, “Gemma”라는 이름을 그대로 사용하는 것은 제한되며, 별도의 명칭을 부여해야 합니다.
- 사용자 책임 명시 : 모델 활용 과정에서 발생하는 결과 및 문제에 대한 책임은 전적으로 사용자에게 있습니다.
정리하면, Gemma 3 270M은 자유롭게 사용하고 수정·배포할 수 있지만, 명칭 사용과 책임 규정에 유의해야 하는 오픈소스 모델입니다.
출처
- 구글 Gemma 라이선스 : https://ai.google.dev/gemma/terms
Gemma 3 270M 직접 사용해보기
이 섹션에서는 로컬 환경에서 Gemma 3 270M을 실행하는 두 가지 방법을 단계별로 안내합니다.
- 첫째,
transformers를 활용한 Python & Hugging Face 방식 - 둘째, 손쉬운 실행이 장점인 Ollama 방식
개발·실험 유연성이 필요하다면 Python 방식을, 빠른 체험과 배포 편의를 원하신다면 Ollama 방식을 권장합니다.
1) Python & Hugging Face
사전 준비 안내
- 운영체제 : Windows / macOS / Linux에서 모두 동작합니다.
- GPU 여부 : GPU 없이 CPU만으로도 실행 가능하지만, 속도 개선을 위해 NVIDIA GPU 사용을 권장합니다.
- 디스크/네트워크 : 최초 실행 시 모델 가중치 다운로드가 필요합니다. 네트워크 연결과 수백 MB 수준의 여유 공간을 확보합니다.
- Python 설치 : Python 공식사이트에서 현재 운영체제에 맞는 버전을 설치해줍니다.
- 모델 다운로드 : 로컬에서 사용할 Gemma 3 270M 버전은 구글 허깅페이스에서 내려받을 수 있으며, 이번 예시에서는
gemma-3-270m-it모델을 활용합니다.
실행 환경
- 운영체제 : Windows 환경
- 모델 버전 : gemma-3-270m-it
- Python : 3.10.11
- transformers : 4.55.2
- torch : 2.6.0 + cu126
- accelerate : 1.10.0
- GPU : NVIDIA GeForce RTX 4060 Ti (VRAM 16 GB)
패키지 설치
# Windows PowerShell
pip install transformers accelerate
pip install torch==2.6.0 --index-url https://download.pytorch.org/whl/cu126
코드 작성
# python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
MODEL_NAME = "Path/to/gemma-3-270m-it" # 실제 모델 카드명으로 교체
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
# 기본 로드(CPU 또는 GPU 자동)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.8,
top_p=0.9,
)
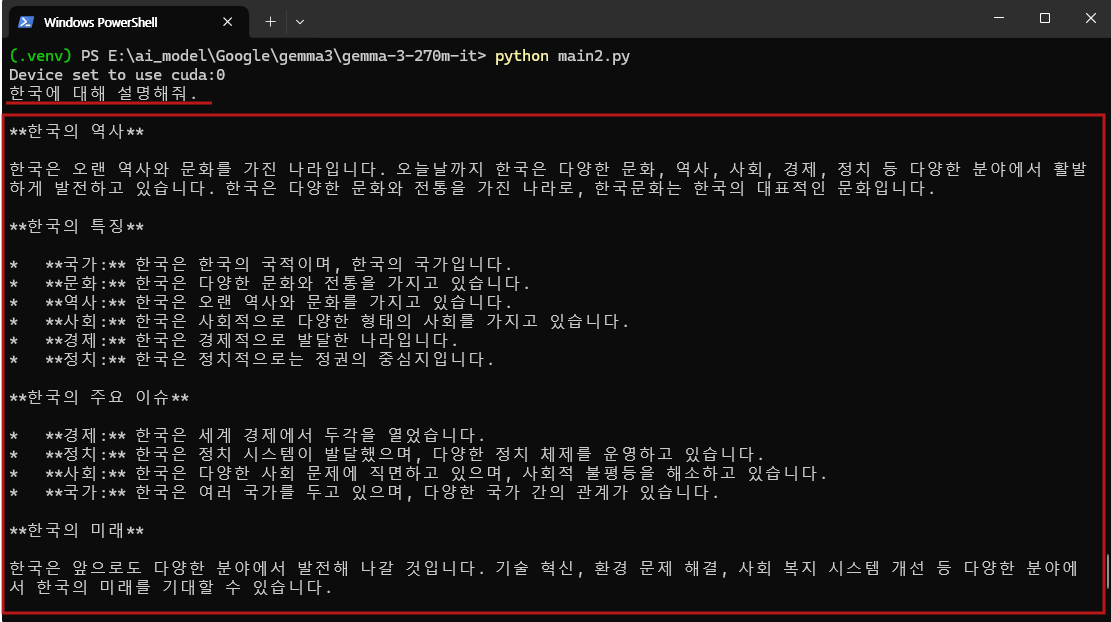
prompt = "한국에 대해 설명해줘."
out = pipe(prompt)[0]["generated_text"]
print(out)
실행 결과
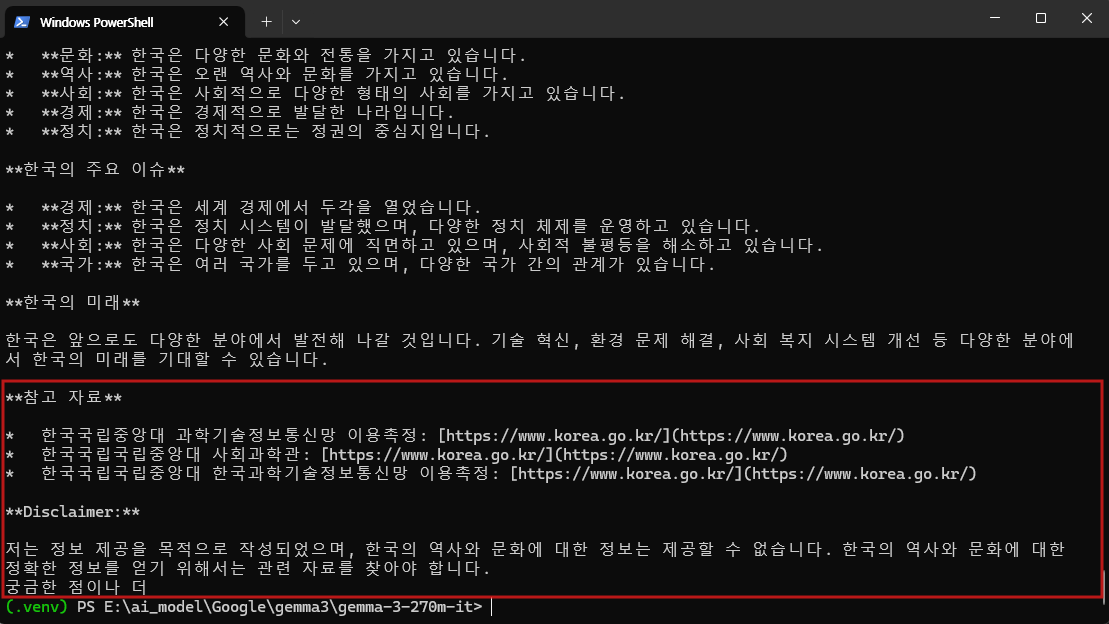
gemma-3-270m-it 모델은 입력된 질문을 이해하고 기본적인 형식을 갖춘 답변을 생성하는 능력을 보였으나, 정확성과 정보의 깊이 면에서는 한계가 있었습니다. 응답은 구조적으로 구분되어 있었지만 구체적인 사실보다는 일반적인 서술에 머물렀으며, 반복되는 표현으로 인해 가독성도 낮았습니다.
실행 과정에서는 약 2.4GB의 VRAM을 사용했고, 출력까지 약 10초가 소요되었습니다. 자원 사용량은 가벼운 편이었으나 응답 속도는 최신 경량 모델과 비교하면 다소 느린 수준이었습니다.
종합적으로 본 모델은 일반적인 대화나 복잡한 추론보다는 텍스트 분류, 감성 분석, 데이터 추출과 같은 명확히 정의된 작업에서 더 효율적으로 활용할 수 있는 모델로 보입니다.
아래 이미지는 실행 결과 이미지 입니다.
2) Ollama
사전 준비 안내
- 운영체제 : Windows / macOS / Linux에서 모두 동작합니다.
- GPU 여부 : GPU 없이 CPU만으로도 실행 가능하지만, 속도 개선을 위해 NVIDIA GPU 사용을 권장합니다.
- 디스크/네트워크 : 최초 실행 시 모델 가중치 다운로드가 필요합니다. 네트워크 연결과 수백 MB 수준의 여유 공간을 확보합니다.
- Ollama 설치 : Ollama 공식사이트에서 현재 운영체제에 맞는 버전을 설치해줍니다.
실행 환경
- 운영체제 : Windows 환경
- 모델 버전 : gemma-3-270m-it
- Ollama : 0.11.4
- GPU : NVIDIA GeForce RTX 4060 Ti (VRAM 16 GB)
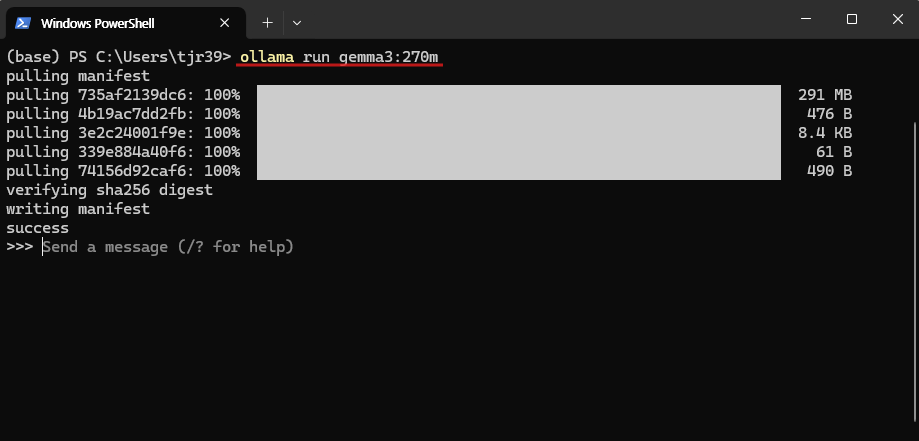
모델 다운로드 및 실행
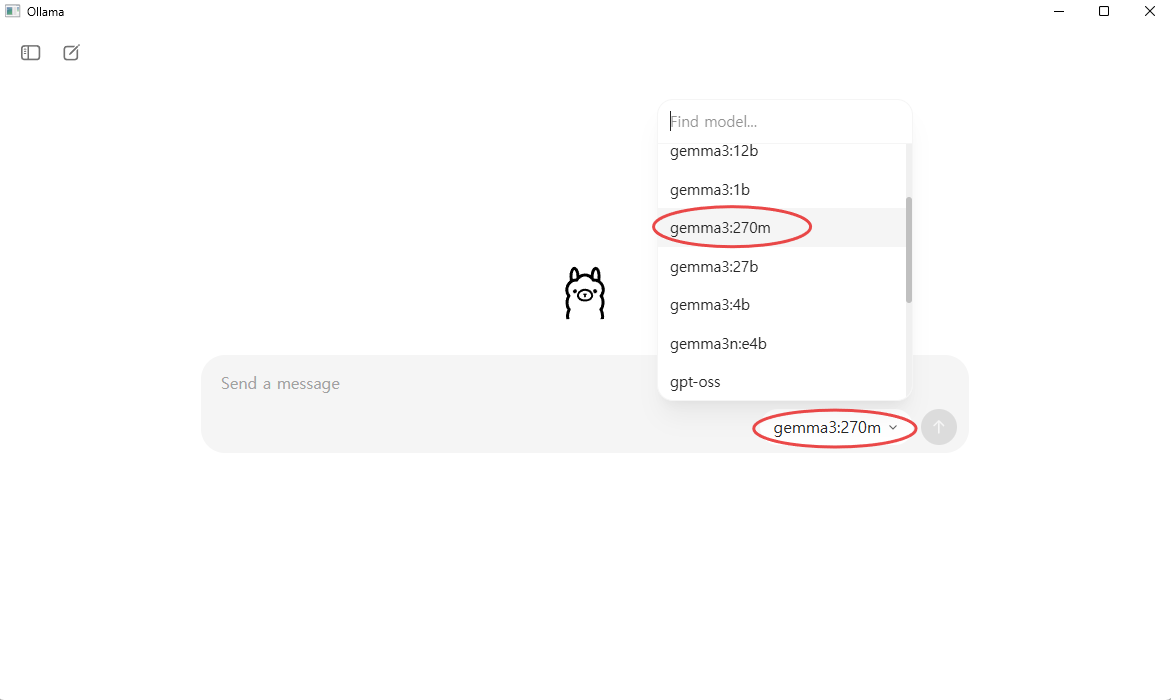
Ollama를 실행한 뒤 프롬프트 창에서 모델 선택 버튼을 눌러 gemma3:270m 모델을 선택하면 즉시 실행하여 대화를 시작할 수 있습니다. 해당 모델이 로컬에 없을 경우 자동으로 다운로드가 진행된 후 실행됩니다. 만약 목록에 모델이 보이지 않는다면, 터미널에서 직접 다운로드 명령어를 실행하면 정상적으로 추가됩니다.
아래 이미지는 Ollama에서 Gemma 3 270M을 실행한 예시 화면입니다.
[직접 다운로드 명령어]
# 아래 두 명령어 중 하나를 사용할 수 있습니다.
ollama pull gemma3-270m-it # gemma3-270m-it 모델만 다운로드
ollama run gemma3-270m-it # gemma3-270m-it 모델 다운로드 후 바로 실행
실행 결과
Ollama 환경에서 gemma3:270m 모델을 실행한 결과, 응답은 간결하고 구조적으로 잘 정리된 형태로 생성되었습니다. 실행 과정에서 약 1.8GB VRAM이 소모되었고, 응답까지 걸린 시간은 약 1초로 매우 빠른 속도를 보였습니다.
로컬 환경에서 Python을 통해 직접 실행했을 때보다 훨씬 효율적이고 안정적인 결과를 얻을 수 있었으며, 출력 형식도 비교적 명확했습니다. 다만, 응답 내용은 짧고 단순한 개요 수준에 그쳐 세부적인 설명이나 깊이 있는 정보 제공에는 한계가 있었습니다.
종합적으로 Ollama 실행은 가벼운 자원 소모와 빠른 응답 속도라는 장점을 보여주었으며, 간단한 요약이나 기본 정보 제공과 같은 목적에 특히 적합한 결과를 보였습니다.
📝 마무리
Gemma 3 270M 모델은 초소형 언어 모델로서 빠른 속도, 적은 용량, 낮은 GPU 사용량이라는 장점을 지니고 있습니다. 하지만 모델의 특성상 제공하는 답변은 간단하고 개요 수준에 머무르는 경우가 많기 때문에, 일반 대화형 활용보다는 텍스트 분류, 감성 분석, 데이터 추출과 같은 특정 목적에 맞게 사용하는 것이 적절해 보입니다.
특히 로컬 환경에서 직접 활용하고자 하는 경우에는 Python 환경을 통한 실행보다 Ollama를 활용하는 방식이 훨씬 간편하고 효율적이므로, 가벼운 테스트나 실사용을 계획하는 사용자에게 권장할 만합니다.
종합적으로 Gemma 3 270M은 작고 빠르며 효율적인 실험용·특화형 모델로, 목적에 맞게 활용할 때 가장 큰 가치를 발휘하는 모델이라고 평가할 수 있습니다.
읽어주셔서 감사합니다. 😊
[참고 링크]
👉 Python 공식사이트 : https://www.python.org/downloads/
👉 Ollama 공식사이트 : https://ollama.com/download
👉 구글 허깅페이스 : https://huggingface.co/google/gemma-3-270m-it/tree/main