ComfyUI 사용법 가이드: 로컬 PC에서 이미지 생성 AI 쉽게 시작하기
ComfyUI 사용 가이드 (Windows 11 기준)
ComfyUI는 Stable Diffusion 기반의 노드형 이미지 생성 툴로, 기존 프롬프트 입력 방식의 한계를 극복하고 직관적인 시각적 구성과 세밀한 제어를 가능하게 합니다. Windows 환경에서 로컬 실행이 가능하며, 초보자도 코딩 없이 고품질 이미지를 쉽게 만들 수 있어 주목받고 있습니다.
이 가이드는 설치부터 이미지 생성까지 처음 사용하는 사람도 따라할 수 있도록 단계별로 설명합니다.
1. ComfyUI란 무엇인가요?
ComfyUI는 Stable Diffusion을 포함한 다양한 텍스트-투-이미지(Text-to-Image) 생성 모델을 노드-그래프 방식으로 구성하고 실행할 수 있는 오픈소스 도구입니다.
기존의 단순 입력형 UI와 달리, 체크포인트 불러오기, 텍스트 인코딩, 샘플링 등의 과정을 블록 형태의 노드로 시각화하여 사용자가 직접 조립하듯 워크플로우를 구성할 수 있습니다.
2. 어떤 모델을 사용할 수 있나요?
ComfyUI는 Stable Diffusion을 포함한 다양한 이미지 생성 모델뿐 아니라, 영상 생성까지 지원하는 범용적인 생성 도구입니다. 단순한 텍스트→이미지 모델은 물론, 스타일 제어, 일관성 유지, 고해상도 출력 등에 특화된 모델들도 유연하게 조합하여 사용할 수 있습니다.
대표적으로 활용 가능한 주요 모델은 다음과 같습니다.
- 동영상 생성 모델
- Wan2.1 (Video) : Text-to-Video, Image-to-Video 지원, 480/720P, 8GB VRAM에서 실행 가능
- HunyuanVideo : 13B 파라미터, 이미지/비디오 생성 모두 지원
- Marey Realism v1.5 : API 기반, 1080p, 상업적 안전성 보장
- Flux 계열 모델 (Stable Diffusion 호환)
- Flux.1 시리즈 : Fill, Redux, Depth, Canny 등 다양한 기능 지원, LoRA 및 ControlNet 등과 네이티브 호환
- Flux Ultra : API 노드로 사용 가능, 고품질 이미지 생성 지원
- 외부 API 통합 텍스트·이미지 모델
- OpenAI GPT‑Image‑1 : GPT-4o 기반 이미지 생성 모델, 현재 베타 API로 제공
- Stable Image Ultra / Runway Gen‑4 / Google Veo2 / Vidu 등 : 다양한 외부 API 연동을 통한 고성능 이미지/비디오 생성 지원
- 기타 텍스트→이미지 오픈 모델
- HiDream-I1 : 17B 파라미터, 개인 및 상업용으로 사용 가능한 MIT 라이선스 기반 모델
- Cosmos-Predict2 : 텍스트→이미지, 이미지→비디오 등 다양한 변환을 위한 모델, 상업적 사용 가능, 템플릿 및 워크플로우 지원
- 기타 모델 : Stable Diffusion, Hunyuan-DiT, CivitAI Pony 등 다양한 오픈소스 기반 모델 활용 가능
참고 : 각 모델은
ComfyUI Manager,Custom Nodes,API 노드또는 직접 설치를 통해 추가할 수 있습니다.
3. 설치 방법
2-1. 통합 설치 파일 (가장 간단)
ComfyUI를 처음 사용하는 경우, 복잡한 설정 없이 바로 실행할 수 있는 통합 설치 프로그램 사용을 추천드립니다. ComfyUI는 현재 Windows와 macOS 환경을 모두 지원합니다.
1) 아래 링크에서 사용자 환경에 맞는 ComfyUI 설치 파일을 다운로드합니다.
2) 다운로드한 설치 파일을 실행합니다.
🔗 ComfyUI 공식 다운로드 페이지 : https://www.comfy.org/download
ComfyUI 통합 설치 프로그램을 실행하면 아래와 같이 첫 단계에서 GPU 종류를 선택하는 화면이 나타납니다.
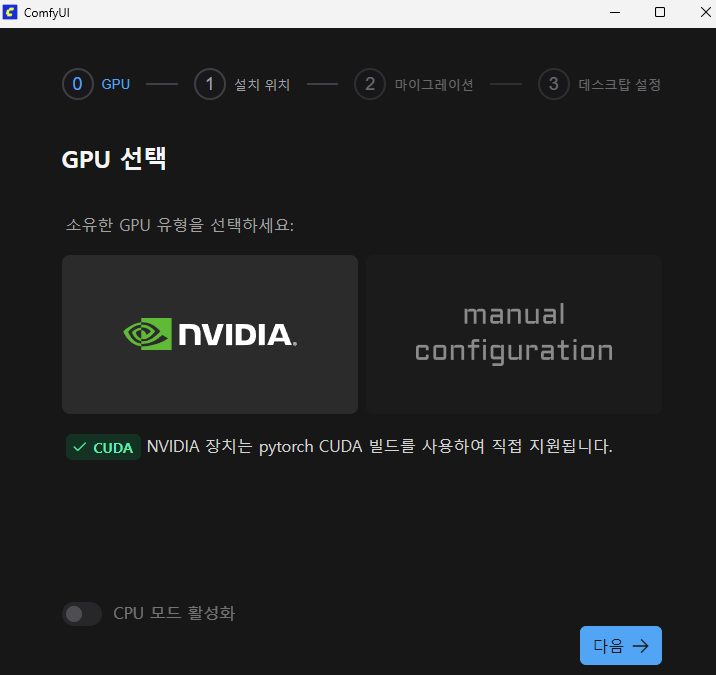
출처: ComfyUI 통합 설치 프로그램
- NVIDIA (NVIDIA GPU 사용 및 필요 패키지 자동 설치)
: 필요한 PyTorch CUDA 패키지와 관련 구성 요소가 자동으로 설치되어 ComfyUI를 GPU 환경에서 최적화된 상태로 실행할 수 있습니다. - manual configuration (수동 패키지 설치 – 고급 옵션)
: 필요한 패키지를 사용자가 직접 설치해야 하며, 설치하지 않으면 ComfyUI가 정상적으로 작동하지 않습니다. - CPU 모드 활성화 (GPU가 없는 경우 설치)
: GPU 없이 실행 가능하지만, 이미지 생성 속도는 GPU 환경에 비해 매우 느릴 수 있습니다.
3) 이후 안내되는 순서에 따라 설치를 진행하시면 됩니다. 필요한 패키지와 환경 구성은 설치 프로그램에서 자동으로 처리되며, 별도의 복잡한 설정 없이 ComfyUI를 바로 실행하실 수 있습니다. 설치가 완료되면 ComfyUI가 자동으로 실행되며, 바탕화면에 실행 아이콘도 함께 생성됩니다.
출처: ComfyUI 시작 화면
2-2. Git 수동 설치
이 방식은 ComfyUI를 GitHub에서 직접 내려받아 설치하는 방법입니다. 통합 설치 프로그램을 사용하지 않고, 사용자가 직접 Python 환경과 라이브러리를 구성해야 하므로 다소 복잡할 수 있습니다. 고급 사용자나 커스텀 설정이 필요한 경우에 적합합니다.
먼저, 아래 ComfyUI GitHub 저장소에서 코드를 다운로드합니다.
- ComfyUI GitHub 저장소 : https://github.com/comfyanonymous/ComfyUI
- Git 명령어 다운로드 :
git clone https://github.com/comfyanonymous/ComfyUI.git
# ① 명령어 입력을 위한 터미널 실행
Windows에서는 PowerShell 또는 명령 프롬프트(CMD), Windows Terminal 등을 사용할 수 있습니다.
# ② 가상환경 생성 및 활성화 (선택)
cd C:\ComfyUI # GitHub에서 클론한 ComfyUI 폴더로 이동
python -m venv venv # 가상환경 생성
.\venv\Scripts\activate # 가상환경 활성화 (Windows 기준)
# ③ 의존 패키지 설치
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 # CUDA 12.1 버전에 맞는 PyTorch 설치
pip install -r requirements.txt # ComfyUI 실행에 필요한 기타 패키지 설치
# ④ 실행
python main.py # ComfyUI 실행
3. ComfyUI 인터페이스 주요 영역 설명
아래는 ComfyUI 실행 화면에서 자주 사용되는 UI 구성 요소의 명칭과 기능 설명입니다.
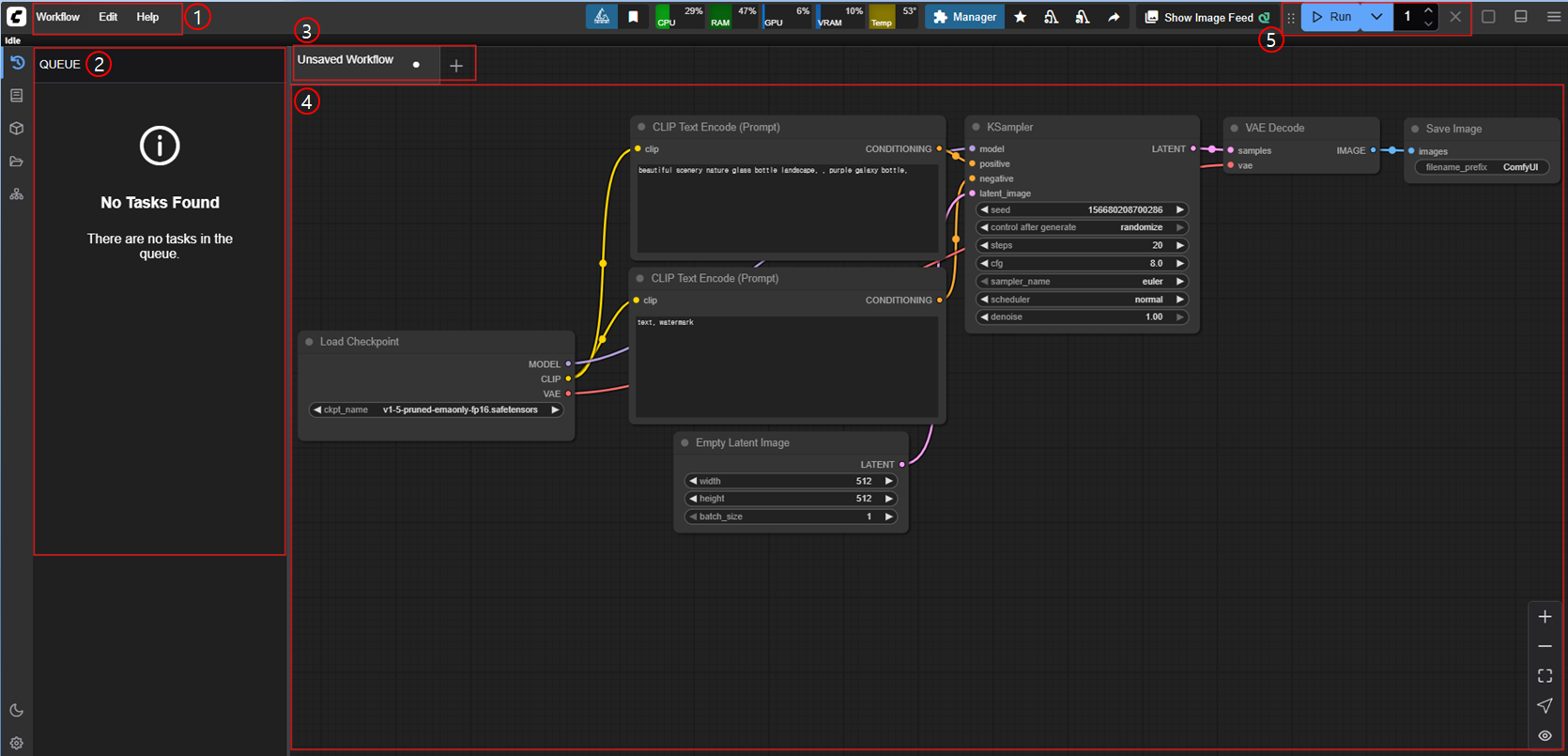
| 영역 | 설명 |
|---|---|
| ① 메뉴바 (좌측 상단) | Workflow, Edit, Help 등 메뉴가 위치하며, 워크플로우 저장, 편집, 도움말 기능 제공 |
| ② 작업 큐 패널 (좌측) | QUEUE 라벨 하단에 실행 대기 중인 작업 목록이 표시됨. 현재 작업이 없으면 "No Tasks Found"로 표시됨 |
| ③ 탭 영역 (중앙 상단) | Unsaved Workflow 등의 이름으로 여러 작업 탭을 동시에 열 수 있음 |
| ④ 워크플로우 캔버스 (중앙) | 중앙의 넓은 작업 공간. 노드들을 배치하고 연결하여 이미지 생성 흐름을 구성 |
| ⑤ 실행 컨트롤 바 (우측 상단) | 실행 버튼(▶), 실행 배치 수(1), 닫기(X) 등 실행 제어 기능 제공 |
4. 이미지 생성 워크플로우 예시
ComfyUI를 설치하고 처음 실행하면 기본적으로 제공되는 워크플로우 예제를 통해 이미지 생성 과정을 쉽게 이해할 수 있습니다. 이 예제를 바탕으로 주요 노드 구성과 작동 방식을 간단히 살펴보겠습니다.
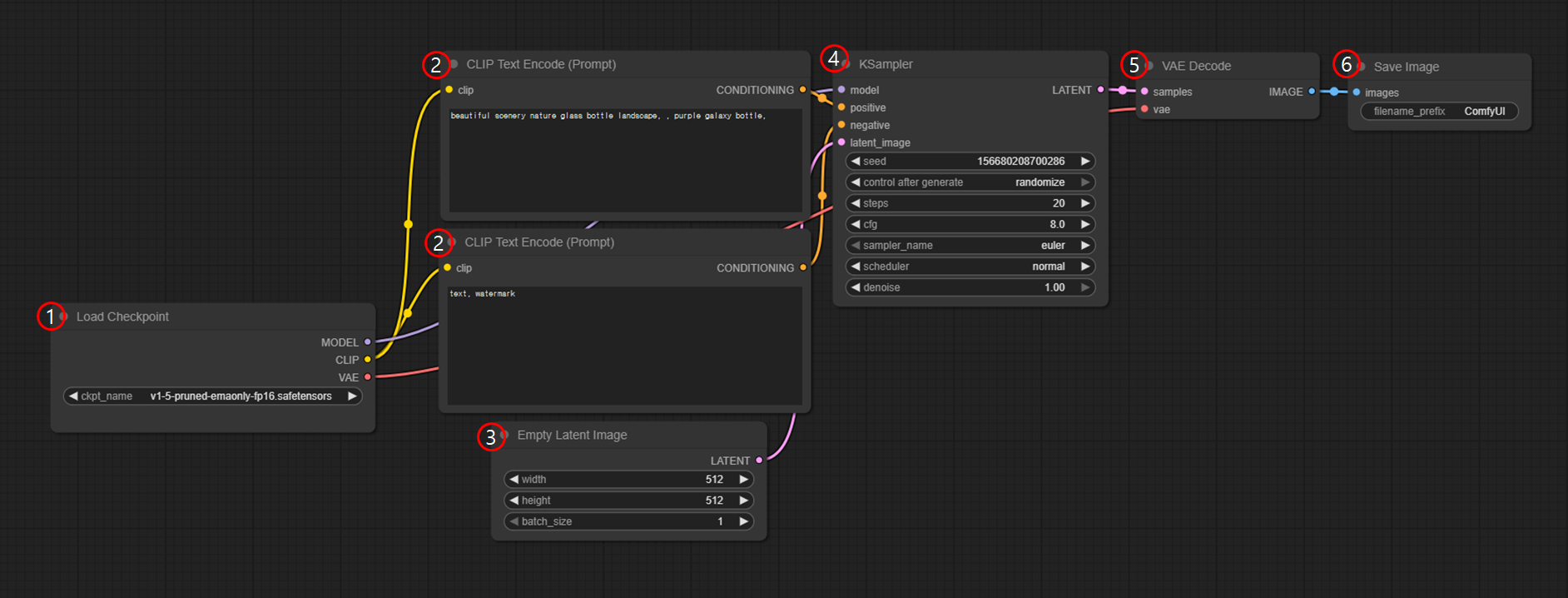
| 노드 이름 | 설명 |
|---|---|
| ① Load Checkpoint | 이미지 생성에 사용할 모델 파일(.safetensors) 을 불러오는 곳입니다. 이 모델이 그림을 그리는 ‘화가’ 역할을 합니다. |
| ② CLIP Text Encode (Prompt) | 모델에게 어떤 그림을 그릴지 알려주는 문장(Prompt) 을 넣는 곳입니다. '예쁜 풍경'과 같이 원하는 요소는 positive, 피하고 싶은 요소는 negative로 나눠서 입력합니다. |
| ③ Empty Latent Image | 그림을 그릴 도화지의 크기(width, height) 를 설정하는 곳입니다. 처음 이미지를 어떤 크기로 만들지 정하는 단계입니다. |
| ④ KSampler | 실제로 그림을 그리는 작업이 이뤄지는 중심 노드입니다. 얼마나 정교하게 그릴지(steps), 창의성 정도(cfg) 등을 조절합니다. |
| ⑤ VAE Decode | 모델이 그린 결과는 처음엔 눈에 안 보이는 형태(latent)입니다. 이걸 눈에 보이는 이미지로 변환(Decode) 해주는 단계입니다. |
| ⑥ Save Image | 완성된 그림을 파일로 저장하는 곳입니다. 저장될 파일 이름도 여기에서 지정할 수 있습니다. |
📌 위 구성은 텍스트 프롬프트를 입력해 이미지를 생성하는 가장 기본적인 형태입니다. 이후 필요에 따라 다양한 이미지 생성 모델이나 ControlNet, LoRA, Style 노드 등을 추가하여 워크플로우를 확장할 수 있으며, 이를 통해 보다 정교하게 이미지 생성 과정을 조절할 수 있습니다.
5. ComfyUI 장점 (웹 기반 이미지 생성 플랫폼 대비)
ComfyUI는 웹에서 제공되는 이미지 생성 플랫폼과 비교해 더 높은 자유도, 유연한 설정, 강력한 확장성을 제공합니다. 특히 로컬에서 직접 작동하기 때문에 데이터 보안 측면에서도 우수하며, 반복 작업이나 고급 커스터마이징이 필요한 사용자에게 적합한 도구입니다.
| 구분 | ComfyUI | 웹 기반 이미지 생성 플랫폼 |
|---|---|---|
| 자유도 | 모든 생성 과정을 노드 단위로 커스터마이징 가능 | 프롬프트 중심의 제한된 설정만 제공되는 경우가 많음 |
| 모델 선택권 | 다양한 Stable Diffusion 기반 모델 및 LoRA, ControlNet 등 직접 설치 및 조합 가능 | 플랫폼에서 제공하는 일부 모델에만 접근 가능 |
| 해상도/속성 조절 | 이미지 해상도, 샘플링 방식, 시드 고정, 배치 수 등 세부 파라미터 직접 제어 가능 | 일반적으로 해상도나 시드 제어가 제한됨 |
| 데이터 보안 | 모든 작업이 로컬에서 이루어져 프라이버시 보장 | 사용자의 프롬프트나 이미지가 서버로 전송됨 |
| 워크플로우 저장 및 공유 | 생성 워크플로우를 .json 형식으로 저장 및 재사용 가능 | 대부분 세션 기반으로 저장 불가 또는 제한적 |
| 확장성 | 타사 API 연동, 커스텀 노드 추가, 자동화 스크립트 가능 | 플랫폼 제공 기능 외 확장이 어려움 |
| 비용 효율성 | 한 번 설치하면 추가 비용 없이 장시간 사용 가능 | 대부분 사용량에 따라 유료 과금 발생 |
6. 자주 발생하는 문제 해결
ComfyUI를 사용할 때 초보자들이 자주 겪는 문제와 그에 대한 해결 방법을 아래와 같이 정리했습니다.
| 증상 | 원인 · 대처 |
|---|---|
Torch CUDA 오류Torch not compiled with CUDA enabled | PyTorch가 GPU 지원 없이 설치된 경우 발생합니다. ✅ 해결: 아래 명령어로 CUDA 버전이 포함된 PyTorch 재설치 pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 |
| 모델 메모리 부족 오류 (VRAM 부족) | 고용량 모델을 8GB 이하 GPU에서 실행할 경우 발생합니다. ✅ 해결: --medvram, --lowvram 등의 옵션 사용 또는 SD 1.5 같은 경량 모델로 전환 |
| 실행 시 흰 화면 또는 UI가 로드되지 않음 | 브라우저 캐시 문제 또는 포트 충돌로 인해 UI가 정상적으로 표시되지 않을 수 있습니다. ✅ 해결: 브라우저 캐시 삭제, 다른 브라우저로 접속, 혹은 포트 변경 시도 |
| 노드 검색 안 됨 / 커스텀 노드 미표시 | custom_nodes 폴더 구조 오류 또는 오탈자 발생 시 인식되지 않습니다. ✅ 해결: 경로/폴더명 정확히 확인 후 ComfyUI 재시작 |
7. 더 알아보기
- 공식 ComfyUI : https://www.comfy.org/
- 공식 ComfyUI GitHub : https://github.com/comfyanonymous/ComfyUI
- ComfyUI Wiki : https://comfyui-wiki.com/ko
- Stable Diffusion Art 커뮤니티 : https://stable-diffusion-art.com/models/
마무리
지금까지 Windows 환경에서 ComfyUI를 설치하고 첫 이미지를 생성하기까지의 기본적인 과정을 함께 살펴봤습니다. 처음엔 조금 복잡해 보일 수 있지만, 익숙해지면 정말 다양한 이미지를 원하는 대로 자유롭게 만들어낼 수 있습니다.
노드 기반의 UI를 잘 활용하면 단순한 텍스트 프롬프트만으로는 어려웠던 세부적인 이미지 생성까지 내 마음대로 조절할 수 있게 됩니다. 다양한 모델과 커스텀 노드도 적극적으로 실험해보면서 나만의 멋진 워크플로우를 만들어 보세요.
끝까지 읽어주셔서 감사드리며, 멋진 AI 창작을 응원합니다! 😊